> The internet transport ecosystem has been ossified for decades now, and QUIC breaks out of this ossification
But it's still just a layer on top of UDP, and still implemented at the application, like in the past. So how is the ossification broken?
Every app has to implement it itself rather than calling a syscall and letting the OS deal with its complexities (same as for TLS, making fewer apps implement it without a lot of extra work). Which also increases context switching. In the future more protocols will be built on top of QUIC, expanding the user-space stack, increasing fragmentation of application-space IP stacks. And are network cards now going to start implementing it?
It's painful to watch us stride headlong into the future depending on band-aids because surgery is too complicated.
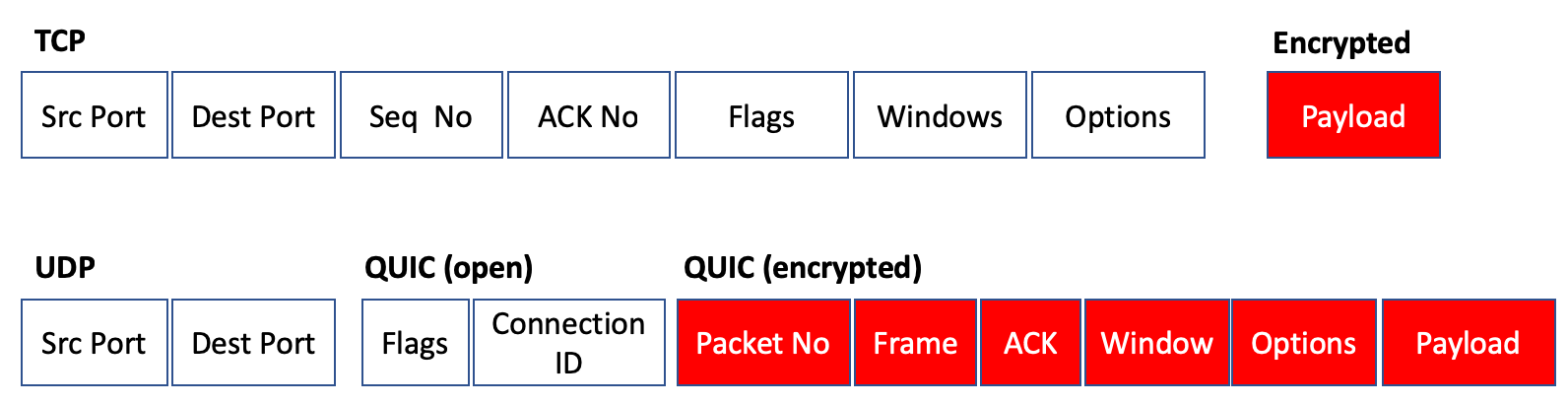
The “ossification” that QUIC deals with is primarily about internet routers who decide to dig into their IP packets. https://http3-explained.haxx.se/en/why-quic/why-ossification Many have optimisations around TCP and long-standing TCP characteristics, which they are able to do because the TCP headers are unencrypted. This led to TCP being difficult to improve, because of all the implementations out there making assumptions and doing these optimisations that weren’t compatible with new developments, or worse, dropping traffic with new, unrecognised TCP options.
In comparison QUIC is almost 100% encrypted, and exposes comparatively little data for routers to ossify on. So even if network cards start optimising, they can only do so much damage because they are given very little information. For example, there is no way for them to do their own special per-stream flow control, because the stream identifier is encrypted. The only things visible are the UDP src/dest port, the QUIC connection ID, and a minimal set of flags. Most important is that the flow control information is encrypted, which is one of the main things TCP couldn’t improve on due to ossification.
That’s not to say the number of implementations stops being a problem — just means that you can actually use QUIC version numbers and negotiate features at the endpoints and ignore anybody along the routes. So you can get adoption of new ideas much more quickly.
Ah, the old middleboxes excuse. Changing TCP would break the middleboxes, so instead we'll invent a brand new protocol which is (theoretically) ignored by the middleboxes. The idea being if you slip something in via UDP, nobody will notice, and then you encrypt it so the middleboxes give up on it.
This assumes that lack of transparency is the only way forward. I'd argue that IP and TCP ossified not because of transparency, but because the design didn't make it easy enough to simultaneously remain compatible while adding new functionality. Yet we know a transparent, grokable, mungeable, backwards-and-forwards-compatible protocol that plays well with middle boxes is doable: HTTP. We could design lower-level protocols to have the same design properties, with both long-lived backwards compatibility and the ability to adopt new functionality. If the problem is with middleboxes, then the solution shouldn't be "how can we avoid them", but "how can we make a protocol that works well with them".
(As a side note, a lack of transparency has chilling effects. Since the adoption of TLS v1.3, more and more TLS security has been broken in order to provide the necessary IT functions of traffic inspection, caching, routing, classifying, shaping, and blocking. Nation states will need to continue creating their own fragmented walled gardens, and continue invading privacy more, precisely because we're giving them less control over how they manage these functions which are a matter of national policy. You can't software you way out of a process problem.)
You're arguing for the "smart network" approach. This approach already failed. Some HN readers might not even have been born when that happened. The dumb network won. Perhaps the smart network can be pulled off successfully, but it won't be by humans, and I don't see anybody else around here trying.
The supposed "chilling effects" don't work out in practice. You will sometimes see people saying oh, China blocks TLS 1.3. Nope, many of the services you use now have TLS 1.3 and yet still work fine in China. "They just push people to a fallback". Nope, Downgrade Protection means that's exactly the same as just dropping all TLS connections.
TLS 1.3 doesn't change the correct way to interpose, it just makes yet more of the bad ideas that shouldn't work actually not work. If you were doing any of those and they broke, that's not TLS 1.3, that's because you were doing something that we already warned you shouldn't work. Stop doing things that can't work.
And it's true, such people keep demanding "transparency". I think they'd probably avoid some of their problems by just admitting that what they want is at best eavesdropping and that this isn't what other people think "transparency" means. There was a whole thread about this on the TLS working group list earlier in May. We get it, you would like to eavesdrop on people, but you don't like to admit this and you'd prefer if there was some way to pretend everything is fine, while, on the other hand, actually eavesdropping.
What's funniest is that the big players in this game want to play both sides so badly they can't even stop contradicting themselves long enough to write a document. The last version of draft-camwinget-opsec-ns-impact that I reviewed has such an obvious contradiction which I called out, it wants everybody else to use RSA key exchange, so that it can snoop all their TLS traffic, but of course implementers of the draft must forbid RSA key exchange, so that nobody snoops them.
Nah, middleboxes are garbage. The security features they claim to offer are all snakeoil checkbox-ware, businesses and government agencies/state-controlled telcos use them because they have a nominal compliance obligation to do a thing so they buy a middlebox that they can wave their arms at when the auditor/commissar comes around.
Generalized "optimizer" middleboxes don't actually work in real world performance testing, with the possible exception of machines that apply dumb global queue discipline to fix a defective buffering device somewhere else in the network, but these don't need to do packet inspection at all, just byte-counting/early-drop.
Traffic shaping mostly only works in the endpoint, but aside from that, all you need is src/dest/byte count to do as good as traffic shaping as it is possible to do without being circumvented trivially (by the far end, without the users knowledge, thanks to the web letting the server script the client)
If you want to run a totalitarian state, do what actually competent totalitarian states do and take over the endpoints.
I'll give you that a lot of the middlebox problems are because they are garbage, however...
Dismissing the security features they are ostensibly delivering snakeoil is more than a bit unfair. There is a legit security context where absolute transparency & auditability is the right design objective, rather than absolute privacy. I'd argue the greatest failing we've seen with the evolution of TLS was the failure to recognize and address that reality.
For TLS if you build a middlebox which obeys the protocol invariants (e.g. see RFC 8446 section 9.3) then you're golden. This isn't so hard, it's almost embarrassing that anybody needed these writing down, but evidently they did.
This is true for QUIC too. Obey the invariants. You don't need to read all these complicated documents, just the invariants.
Now of course there are obstacles. First doing this is expensive. Doing things that don't obey the invariants (many of which also destroy your security) was cheaper. Too bad. If your supposed "legit security context" is so valuable you'll afford this.
Second doing this in effect requires confessing to the people you were "legitimately" giving "transparency & auditability" that you are snooping on them. Too bad, if your supposed "legit security context" really was what you pretend this conversation will be easy for you.
Yes, yes, you must obey the invariants. The trick is in the consideration of the invariants.
The problem isn't the cost or the "confession", because those are already part of the context. The problem is that in the process it creates new security risks that needn't be there but for the choices made by TLS.
In particular, the lack of separation of concerns between protections from eavesdropping, tampering and forgery proves to be quite problematic for environments where forgery & tampering are a serious concern, but eavesdropping is the nature of the context. It's why you see proposals for ugly hacks of TLS like eTLS; it's doing more harm than good.
Sure, in terms of raw features it looks like being able to uncouple the integrity verification would enable a client to choose to say "You can see what I'm doing, but you can't tamper with it". There are researchers who would like to do that, and last I looked the TLS working group invited them to turn that into an actual draft.
But it's essential in practice to remember that overwhelmingly the environment people are interested in is the Web, and on the Web those aren't actually different things again, in practice.
For example, suppose you're OK with me eavesdropping your Amazon purchases. You're buying a Lego robot for your daughter's birthday, you work for the investment bank, it's nice that we even let you do that from work and clearly we can't just let you do whatever you want with no oversight or you might rob us blind. We have a hypothetical TLS 1.4 which lets you opt in to this eavesdropping but nothing else, and you've done exactly this.
We eavesdrop your purchase, we were prevented from tampering with it. But, this is the Web. The eavesdropped TLS session contains a secret cookie value, which identifies you to Amazon. We can use this to impersonate you and do whatever we want, just as if we were able to tamper with your TLS session. The apparently more limited permissions are a mirage.
> But it's essential in practice to remember that overwhelmingly the environment people are interested in is the Web, and on the Web those aren't actually different things again, in practice.
If the problem is the web, then the problem should be addressed by the web, not TLS.
...and of course, part of the problem is that we've conflated nearly everything to the "web", so thinking that the web is somehow removed from this problem is a mistake.
> We eavesdrop your purchase, we were prevented from tampering with it. But, this is the Web. The eavesdropped TLS session contains a secret cookie value, which identifies you to Amazon. We can use this to impersonate you and do whatever we want, just as if we were able to tamper with your TLS session. The apparently more limited permissions are a mirage.
Yup, that's a legit problem, though I'd argue it actually further reinforces my point. This is a good example of a problem that stems from conflating multiple security concerns, rather than addressing them as separate concerns.
If there's an acknowledgement that your authenticated & tamper proof session is fully exposed to eaves dropping, then you start using the authentication mechanism itself to identify people or you develop an additional identification mechanism that is resilient to replay attacks (both of which are entirely possible) or people just inherently become aware of the reality that buying stuff on Amazon from an eavesdropping environment means that they will be impersonated on Amazon. What you don't do is think a "secret cookie value" is a secret when it so clearly is not.
> DPI security middleboxes for the enterprise are always and without exception snakeoil and/or checkboxware.
If you don't care that your broker may be selling you down the river, or whether information is being leaked to an intelligence operative, that's a fair assessment. Unfortunately, much as we might wish otherwise, there can be conflict between privacy solutions and security solutions. The trick is to find a way to service both without compromising either.
If it's legitimate security it should've done via an explicit proxy not an attempt to break into every conversation and hope it works right 5 years from now.
I deploy these kinds of network security solutions to large enterprises as part of my job (typically healthcare customers, from a network MSP/MSSP VAR perspective these days) and as much as I like being paid to continually "fix" broken implicit systems it's not the way to go and never should have been. Either you control the systems or you don't, if you don't fully control you're going to fail at reliably breaking into the conversations to a meaningful level and you probably shouldn't have such critical information on systems you don't control anyways. That or you're trying to control/inspect someone else's system which is exactly what these things are trying to prevent.
> Yet we know a transparent, grokable, mungeable, backwards-and-forwards-compatible protocol that plays well with middle boxes is doable: HTTP
Not all traffic is web traffic, maybe not even most of it. There are so many things that would have absolutely wretched performance if you tried to implement them with HTTP instead of TCP. HTTP is way too generic to be truly performant.
I don't know that I'd hold up HTTP as an example of the way forward. ;-)
That said, the TLS v1.3 thing has been interesting. I tend to look at it more as a case of projecting one security context onto everyone else's security context, and the consequent problems involved. Security is tough like that.
> The “ossification” that QUIC deals with is primarily about internet routers who decide to dig into their IP packets.
Being 'opaque' to the network is not a foolproof choice, since it also makes stuff like NAT, congestion control and QoS a lot less robust. By exposing connection identifiers to the network, SCTP gains a lot of flexibility wrt. such scenarios compared to QUIC.
> it also makes stuff like NAT, congestion control and QoS a lot less robust
That's a feature, not a bug. NAT is cancer. It killed the open internet by enabling a particular lazy form of "security" that forced everyone to hand control of their most important data to cloud services.
QoS is worse but has less fallout due to less deployment.
>NAT is cancer. It killed the open internet by enabling a particular lazy form of "security" that forced everyone to hand control of their most important data to cloud services.
Personal computers and devices are not allowed to talk to each other on the internet. They are only allowed to talk to specially designated servers -- specially designated by virtue of having a public IPv4 and open port. Enforcement happens through liability: if you put data in a cloud service and the cloud service gets hacked, it's the cloud service's fault, but if you run a program on an open port and the program gets hacked, it's your fault, not the program's fault. This is an arbitrary social choice that follows directly from enshrining NAT as a "best practice." Even the term "open port" presupposes that there is something unnatural about plebian computers talking to each other on the open internet! This effectively forces services to be centralized, or at least pushes very strongly in that direction.
Of course, we can quibble: what about video conferencing? What about gaming? They use direct connections! Yes, but they pay an extraordinarily steep complexity and reliability price to obtain them and the solutions still wind up using centralized servers. They are exceptions that prove the rule because they allow us to observe how "stepping out of line" is discouraged. It's an accidental line drawn by monkies rather than an intentional line drawn by lizard people, but it's strongly enforced and society-shaping all the same.
It's totally wild to consider the social and market consequences of NAT, the unassuming lazy and kludgy security hack. It got out of hand and reshaped the internet, the technology market, and society from the ground up! That's hardly even an exaggeration!
NAT is literally the only thing stopping every single personal device in the world from being hacked. It may be a kludge, but it's the best kludge in all of technology. And what do you have against QoS? Would it be better if your VoIP calls stuttered every time you loaded a fat web page?
> NAT is literally the only thing stopping every single personal device in the world from being hacked.
This is so wrong that it must be satire. NAT provides the very most basic protection possible, easily replicated (and surpassed) by every firewall that comes stock with every modern OS, and is completely insufficient (and not even necessary) to prevent personal devices being hacked.
I'll buy this for firewalls in end-user routers, but if you put the firewall on the personal device it's gonna get disabled the first time it supposedly interferes with a videogame or a movie stream or whatever. :(
NAT enables dogshit endpoint security, yes, but that's the problem. Without NAT as a crutch, endpoint firewalls and service security wouldn't suck. Compared to other feats of security engineering the industry has undertaken in order to make centralized cloud services happen, namely JavaScript and the ability to safely run untrusted code from the nastiest corners of the internet at high performance, this would be downright trivial. It just never happened because we had NAT.
It's really not. Like, really, really not. I won't try to make the case here, but just know that assertions like that aren't going to come across as credible. The systemic effects from NAT have actually made things worse.
The fact that a kid with a port scanner can't remotely connect to and exploit your printer is due to NAT not being able to route the traffic, whether you have a stateful firewall or not. The majority of internet-addressable devices in the world do not have firewalls. Hence, NAT keeps most devices safe from drive-by RCE. There are plenty of attacks to get around that, but by default, nothing else protects random devices like NAT does.
You should be able to ping(6). Can you connect to tcp/22? If not, it shows that my router's stateful packet inspection (SPI) works even when NAT isn't present.
Well first, IPv6 doesn't need NAT, and mostly never uses NAT. If IPv6 devices used NAT, they would be protected. But since they aren't using NAT, they aren't protected. You're right that devices that enable IPv6 (and network routers that give out IPv6 addresses) are not protected by NAT, but luckily it's still a small amount of traffic/devices worldwide. But this is changing, and so NAT won't help people for much longer.
Second, SPI isn't used for security here. It's true that SPI is used by NAT, and that SPI can be used to prevent, say, a specially crafted packet from passing from a public network through a router into a private network. But something other than SPI has to actually enforce that. That "something" is usually extra features of the network stack, like disabling source-routing, reverse-path filtering, ARP filtering, etc. All SPI is doing is helping the NAT engine track the connections it is translating.
For "good faith" traffic (that is, not crafted by an attacker to work around crappy NAT routers) NAT still provides security. Actually it's not NAT at all that's providing the security - it's just the routing. You can't pass traffic from a public network into a private network, and almost all devices behind NAT are on private networks. So NAT provides security merely by keeping devices on a private network.
> But since they aren't using NAT, they aren't protected.
I just demonstrated that protection exists without NAT.
> […] but luckily it's still a small amount of traffic/devices worldwide.
I don't think this is correct. Just about all devices on a cellular/mobile network nowadays are probably using IPv6 natively, with CGNAT for IPv4. That's a lot of devices.
An experiment: temporarily disable Wifi on your cell phone, go to your browser, search of "what is my ip address". Chances are that you'll see an IPv6 address there: if using Google they'll return something an IPv6 address at the top, and a list of different web sites that do the same thing. If you go to a website you'll probably get an IPv6 and an IPv4 address.
> But something other than SPI has to actually enforce that.
Connection tracking is sufficient for most modern protocols (i.e., not (active) FTP):
> A stateful firewall keeps track of the state of network connections, such as TCP streams, UDP datagrams, and ICMP messages, and can apply labels such as LISTEN, ESTABLISHED, or CLOSING.[2] State table entries are created for TCP streams or UDP datagrams that are allowed to communicate through the firewall in accordance with the configured security policy. Once in the table, all RELATED packets of a stored session are streamlined allowed, taking less CPU cycles than standard inspection. Related packets are also permitted to return through the firewall even if no rule is configured to allow communications from that host.
I think we're sort of agreeing on the same things. NAT protects devices, and stateful firewalls protect devices, and if you have neither, you're not protected. My point was that more devices exist behind NAT than come bundled with a stateful firewall, hence NAT protects more devices. The NAT devices/routers might additionally have a stateful firewall (which really only protects the router, not the other devices), but I wouldn't trust it as much as the security of a non-routable network.
> My point was that more devices exist behind NAT than come bundled with a stateful firewall, hence NAT protects more devices.
The popularity of a mechanism does not necessarily correlate with the effectiveness of its security. The fact that we're using IPv4 with NAT+SPI versus IPv6 with SPI is simply an accident of history.
If IPv4 had been designed with 64-bit addresses, or even 48-bit ones (like Ethernet MACs, which we still haven't run out of), then NAT probably would not have been invented, and we'd be using 'simple' (SPI) firewalls (see Cheswick 1994).
> […] but I wouldn't trust it as much as the security of a non-routable network.
Non-routable networks are not more secure than routable ones with SPI; at best the two are equal IMHO. Non-routable networks may actually be worse because of a false sense of security: all it may take is one end-point compromise and the enemy is one the other side of the moat.
Even stateful firewalls don’t protect you from being hacked. Hacks occur when you run untrusted code on your machine. That untrusted code can easily bypass your stateful firewall by initiating a connection to a C&C server.
Surprising that with over a year of discussions about this subject I only first hear of it ?
Would this be the reason why at least tens of millions of consumer routers don't have IPv6 firewalls (technically, opt-in firewalls, but you know how that goes...), and don't have their networks hacked ?
Wait, does it even work with UDP, which doesn't have a concept of "connection" ? (Especially IPv6 (no NAT) UDP ?)
NAT is a hack that only ever existed due to IP address exhaustion, and I’ve yet to find a good reason why congestion control and QoS handling in a router needs anything beyond what is already in the IP headers. SCTP’s flexibility is irrelevant since nobody uses it, arguably because of how much the Internet has ossified around TCP and UDP.
Hey, that's not true. People use it... in the telecom industry and everyone using WebRTC's DataChannel (SCTP over DTLS actually).
The protocol is probably mostly fine, but there are no quality library for using it in a general purpose way. Because of that, no one can really use the protocol to its full designed capabilities anyway (and the ossified network nodes don't help either).
It doesn't matter if SCTP has good features if no one is willing to implement quality libraries for it. The protocol exists for a while and only one general purpose library exists for it that's widely used. And it's not without a lot of flaws and limitations.
There are good reasons no one wants to invest in it, and I'm sure they did consider it.
People don't make these decisions for technical reasons only. Career wise it is a bad choice to spend your time working on pre-existing technologies. You don't become a distinguished engineer by iterating on existing technologies. You become one by being the creator of something new.
I think QUIC is great and does a good job solving the problems it was designed to solve. It is disingenuous to pretend these decisions were made only for technical reasons.
3 of those are related to DataChannels in WebRTC, which at this point is baked into the standard and can't be replaced by another protocol. The SCTP in DataChannels is quite limited, that subset is reasonable to implement somehow.
Only the last one is really general purpose and has had a lot of security issues as well.
Fun fact: I do work on one of those implementations and with another one, and it's out of necessity rather than a career choice.
I know you understand libusrsctp Florent. I created Pion, I feel prety comfortable with SCTP and WebRTC in general as well.
RtcQuicTransport tried to replace SCTP and it didn't work. It would be possible to replace SCTP if something better was available. SCTP has lots of great stuff like FORWARD-TSN. QUIC didn't offer anything compelling over it. Also would come with a huge cost of making WebRTC larger and losing interop with all the existing clients.
libusrsctp has had security issues, but I don't think the protocol is the problem. The issue is C/C++. QUIC implementations are going to have the same class of bugs. Chrome/libwebrtc has plenty of security issues in other areas besides SCTP. Rust/Go doesn't fix everything, but one less thing to worry about at least.
Having a standard doesn't mean you're not allowed to innovate and create another one.
SCTP dates from RFC2960, first draft was published in 1999. It had enough time to get traction, and it didn't. Why would anyone build something new with it now, knowing that it doesn't answer some of the issues with the current Internet?
Even WebRTC's DataChannels were introduced at the IETF in 2012, that's 9 years ago (although ironically, the RFC just got published in January...).
Correct me if I'm wrong, but bypassing NAT, congestion control and QoS is also a benefit when you want to build things like P2P services where you want a direct connection between peers and full control over the connection itself. QUIC will help a lot with those use cases.
I'm happy whenever anyone brings up SCTP. Such a maligned protocol. Congestion control and QoS, however, are a loser's game. If you're running into realistic issues meeting demand due to statistical multiplexing breaking down to the point you must rely on caring about the internal state of traffic streams, you should have thrown more link hardware at the problem long ago.
Many dumb pipes > fewer smarter pipes.
>NAT
Oh, didn't you know, IPv6 was going to solve everything. No more NAT. We're just going to assign everyone an IP at birth so people can continue to ignore the User-Agent/User distinction.
QoS has its uses, and you don't have to look any deeper than TCP/UDP headers for it to be good enough. It allows VOIP/IPTV services to continue working under DDoS conditions for example (ISP level).
Are deep packet inspection and modification boxes really that prevalent outside of the Great Firewall of China and its imitators (Russia has something similar now)?
If QUIC gets in the way of these countries they will simply set up a decrypt-and-recrypt TLS proxy and block connections that don't honor its certificate. Lots of banks and trading firms already do this to their employees for regulatory purposes; there is no technical hurdle.
As someone who has been forced to use ZScaler, there is a slew of technical challenges. 80% of the traffic can be handled "easily" with a custom CA cert, and the rest have varying issues ranging from client problems to server problems to problems in the proxy itself. Just trying to clone a GitHub repo over HTTPS breaks with ZScaler.
I can't comment on this specific product, but if the transparent proxy is causing you so much grief why not just explicitly configure your machine to use the HTTPS proxy?
HTTPS proxies are not voodoo. There are plenty that work quite well.
Actually there is "voodoo" in both transparent and non-transparent proxies, but the bigger problem is that ZScaler's entire raison d'etre is to be a transparent proxy using Carrier-grade NAT. But the point is, ZScaler is a widely-deployed commercial solution, and it does indeed have technical hurdles. Whether it should theoretically work or not, I'm telling you in practice there are problems, and this shouldn't be dismissed out of hand as an outlier.
You really seem to have a beef with this one particular commercial product that I don't have access to.
I've used plenty of other HTTPS proxies and the well-written ones all worked fine. Many are open source. I think you need to direct these comments to whoever is charging you money for this "Zscaler" thing.
But isn’t the “damage” these middleware layers do actually good optimizations/features that people pay for? The ossification is the problem, not the ability to optimize IMHO.
> Every app has to implement it itself rather than calling a syscall and letting the OS deal with its complexities (same as for TLS, making fewer apps implement it without a lot of extra work). Which also increases context switching
Nowhere does RFC9000 say that it has to be implemented in user-space. A kernel-space implementation of QUIC would be conforming. Any OS kernel project (whether open source or proprietary) which would like to develop one is free to do so.
As someone with experience in eBPF and QUIC I can tell you it will be a tough one. QUIC is very complicated and requires some rather sophisticated (and long running) algorithms, and eBPF is [intentionally] rather limited on what it can do.
However there are some interesting use-cases for eBPF in the context of QUIC. E.g. it can definitely be used to route packets by connection IDs.
You're right. I think on the overall we'll gonna have to learn to restrain/harness ebpf somehow, since it will keep growing.
We're already starting to see some complex applications appear over tc+ebpf and I believe I've seen some tcp congestion algorithms prototyped there? Those can be somehow complex already. Crypto could be offloaded to dedicated 'nodes' (as you find in dpdk for example).
But, since you can now chain epbf programs I can imagine some kind of task-graph programming model emerging there allowing for very complex applications. Maybe even specific complex kernel modules that can only be called through ebpf...
In fact I already tried putting most of a high-throughput packet processor there and it's really fun, this feeling of being in 1998 with my first turbo pascal + asm programs. Hard to debug, though.
I hope we'll be able soon to converge on sw archs similar to tbb::flow or cudagraphs or vpp/dpdk pipelines.
The next years are going to be very, very interesting.
It is not really question of OS vs library, but question of standardized API vs ad-hoc API. Most basic networking API is standardized (sockets in POSIX API).
OS's defining the "standard" is very much a 1990s thing; at this point libraries and languages are much more relevant to standardizing things. If you're writing rust, or ruby, or javascript, or C#, or python, or whatever, you're going to be using what your language ecosystem provides you. OS libraries are usually only relevant to C developers writing something low level, and usually they need to write a lot of wrappers and #ifdefs to handle every platforms quirks anyway.
What you're saying is that you personally don't need to write network code that performs socket(), bind(), listen(), accept(), send(), recv(), etc. But the programming language and library you're using is using those calls, to talk to the kernel, which is doing a lot of the work, so your language/library doesn't have to. And it does that using a standard API.
This enables less context switching, faster processing, more uniform behavior, and more portable code. It also means your language/library does not need to implement a TCP parser, which can be quite complicated, and it means the kernel can maintain the more complex network settings that affect your TCP connections, benefit from a shared buffer/cache, network filters, routing, etc. Off-loading protocols into the kernel (or even better, the network card) is a boon to the whole OS and to your individual application.
Because if it's not in the OS, people are going to cheat more often on congestion control to prioritize their own streams. It's a tragedy of the commons. It's only because TCP is ossified and usually in the kernel that we haven't seen a race to the bottom already.
I'm pretty sure that's not how congestion control works... My ISP doesn't honor my congestion control flags. Whatever congestion control I set up ONLY changes things on my side of the ISP connection. And yes, within my LAN, I definitely can prioritize various streams.
The ossification has nothing to do with the distinction between userspace vs kernel. The kernel can implement layer 5 (there are in-kernel HTTP servers!), and userspace programs can implement layer 4 (using raw sockets).
It has to do with the distinction that middleware boxes make between layer 4 and layer 5. NATs and firewalls and assorted traffic optimizers tend to vomit if you pass anything over IP that isn't TCP, UDP, or ICMP.
UDP is, by luck and design, a very thin shim on top of which a "layer 4.5" protocol is very easy to implement. Whether this layering is done in the kernel or in a userspace library is an implementation detail, and one that will probably be obscured even from many userspace programs.
Ironically, one of the proponent documents of QUIC and HTTP/3 (https://http3-explained.haxx.se/en/the-protocol/feature-udp) actually calls out how QUIC doesn't solve this problem either. Middleware boxes are blocking or deprioritizing UDP packets already, so UDP based 4.5 protocols can't solve the very problem they claim to.
Circumventing badly behaving middleware is obviously not actually possible. You can't account for every protocol-breaking/limiting decision every middleware vendor has ever made, and the "they'll come around" argument is a better argument for NOT using QUIC.
No? I'll just link against one of the cross platform libraries that implements it, the same as for any other networking protocol. (Ex https://github.com/microsoft/msquic)
Anything can be implemented in a kernel. But unless it's natively supported in other kernels, networks, and systems, that just means that one kernel is easier to work with.
The big idea behind TCP/IP is that it's a stack which you can use anywhere and everywhere. Not just any network, but any host. To do that, you need it to be portable and ubiquitous. And there is no protocol above OSI layer 4 that is ubiquitous. By nature of being above UDP, QUIC is layer 5 or higher. And it's got more features than other protocols do, meaning it needs more functions.
So not only is it unlikely that it'll be supported like the layer 4 protocols, it's unlikely to be supported by the Berkeley/POSIX sockets API, the one portable network interface specification for every operating system. One solution to all this would be to make QUIC a layer 4 protocol and update the sockets API. But nobody wants to do this because it's hard.
So, we could just have everyone add a layer 5 protocol to their stack, implement it in kernels, NICs, routers, etc, update the sockets API, and wait a few years for adoption. But will that happen? Or will the industry just go "let userspace handle it" like with TLS?
I really do not see how the layers matter. They are just an artificial categorization. E.g. SCTP is both a layer 4 protocol and a layer 5 protocol (SCTP-over-UDP) and as far as I can tell from some quick googling at least both Linux and FreeBSD implement both in their kernels. What matters is if various libcs add QUIC or not.
And the Linux kernel implements other layer 5 protcols like WireGuard.
> The big idea behind TCP/IP is that it's a stack which you can use anywhere and everywhere
For what its worth, Windows 3.x did not come with a TCP/IP stack installed; it was an optional extra. (In the days before Windows 3.x you had to pay for the TCP/IP stack from your network card vendor as an optional extra.)
It wasn’t until Win95 that the OS came bundled with TCP/IP by default, and you could still install other networking protocols like Novel Netware or AppleTalk.
TCP/IP didn’t become the default stack until late into the ‘90s and the “everywhere by default” wasn’t really true until just before the turn of the millennium.
So while QUIC might be in the “early adopters” space for now, everything started that way once. I have no doubt that by 2030 we will see QUIC as a kernel feature in many major operating systems.
I think some versions of Windows 3.x did come with a TCP/IP stack, though it wasn't installed by default even with networking. You had to explicitly install it.
Would it be very wrong to consider QUIC a new type of layer 4 protocol encapsulated in another one (UDP) for compatibility with NATs and other middle boxes?
SCTP is also usually encapsulated in UDP when used in WebRTC data channels, yet I've never heard it being described as anything other than a transport layer protocol.
> it's unlikely to be supported by the Berkeley/POSIX sockets API, the one portable network interface specification for every operating system. One solution to all this would be to make QUIC a layer 4 protocol and update the sockets API. But nobody wants to do this because it's hard.
I can't see why a user-space library couldn't hook the Berkeley sockets API calls and redirect them to a user-space implementation for IPPROTO_QUIC sockets. You may need to use some trick to distinguish native kernel sockets from user-space-implemented ones. (e.g. if you know the kernel only allocates FDs in a given range, use numbers outside that range to identify your user-space-implemented sockets). Someone could add a framework for doing this to the C library.
Actually I believe Windows has a built-in facility for doing this. To implement a new transport protocol in Winsock, you need to provide a transport provider DLL. Normally you'll also have a kernel-mode device driver, which the transport provider DLL calls, and the meat of the protocol implementation will be in that kernel-mode device driver not in the transport provider DLL. But I don't think it has to be that way – I don't believe there is anything stopping a Winsock transport provider from being written entirely in user-space.
I think from their perspective the (Windows and Android) kernel is what causes ossification so moving transport into the app, along with encryption, solves it.
There are also the "middle boxes" that networking researchers talk a lot about. Such devices sit in the middle of a link and easily become unhappy if the packets transmitted do not fit some (possibly outdated or buggy) predefined scheme. Think of cooperate firewalls with "deep pack inspection" that intelligently shut down connections they do not like. Once all middle box vendors start to assume a certain way that a protocol (say, TCP) should behave, it's impossible to change the protocol because it will break the middle boxes.
Encrypting QUIC datagrams prevents middle box vendors from assuming anything about QUIC (at least the encrypted part), so that QUIC can change if there's a need in the future without worrying about supporting legacy middle boxes. Although I do agree using UDP does not allow QUIC to break out from any ossification in UDP itself.
> SCTP has been around for years, but middleboxes still do not recognize it and tend to block it. As a result, SCTP cannot be reliably used on the net. Actually deploying a new IP-based protocol, he said, is simply impossible on today's Internet.
Well, IPv6 shows that it's hard, but possible.
Also see how new broadcast "protocols" were forced on TV manufacturers by various governments worldwide.
Most enterprise security vendors at the moment are advising their customers to block QUIC at the perimeter to force fallback to HTTPS so their TLS decryption can function.
There are valid, ethical reasons for an organization to want to see unencrypted network traffic at their perimeter, and until that problem is solved, you better not go QUIC-only if you are in the business to make money.
You're forgetting the rest of userspace that exists between the application and the kernel.
> moving transport into the app, along with encryption, solves it
This is only a good idea if the application's development moves faster than both the kernel and the rest of the userspace platform - which is a fine strategy if you're targeting old or obsolete platforms, but probably a bad idea if you're targeting currently-supported operating systems with a long support lifetime (like Windows).
It's a bad idea when a major security issue or compatibility problem with a transport or encryption library pops-up (which happens all the time, btw) - as it's part of your application then you don't benefit when the OS vendor ships a security update that your application gets for free. If you used dynamic-load+linking at runtime instead of a statically-linked encryption library then you might get lucky with a drop-in .so/.dll replacement without needing a rebuild, but YMMV.
Doing everything in the app instead of letting the parent platform handle it by default is kinda the software-engineering equivalent of libertarian ideological thinking: it only benefits you if you (and your team) really are far better than the state - otherwise you'll quickly run into problems - and it isn't suitable for the vast majority of the ecosystem.
Let's be honest; we're talking about Chrome here. Chrome auto-updates and Windows (pre-10) did not so bugs will be fixed faster in Chrome. Everybody else is along for the ride.
Right - so in Chrome's case then Google using QUIC as an in-app service is probably fine, as indeed, I trust Google to ship fixes and updates much faster than Microsoft. Also it's far more likely that enterprises have Windows Updates blocked or delayed than Chrome updates - and with Microsoft updates you have to wait for Patch Tuesday every month unless it's something really bad.
My point still stands though, that if you aren't prepared to support an "evergreen" software product for the life of your users, then you should still support OS-provided services, even if you do have your own QUIC support baked-in to your product.
I agree that for updatability it should be something that can be shutdown, reloaded, restarted as simply and with least risk possible. Now I'm thinking that it'll be easier to checkpoint/restore a quic connection than any other thing based on tcp or hidden in the kernel, so you could even do zero-downtime update.
I'm thinking let's just use something like netty or zmq over a simple ip+icmp interface, socket or not. Instead of having everyone learn some ossified quic kernel api... And since everything will soon move to io_uring let's wrap that thing in high-level APIs.
That's not because of ossification, it's because of middleware boxes like NATs and firewalls that will refuse to pass anything that isn't TCP, UDP, or ICMP.
Ah, yes, that wasn't quite clear, sorry. No, I was referring to the ossification of middleboxes/OSes/knowledge/... that made it unviable to support a new IP protocol alongside the existing ones for the general internet case.
Oh yes, when I discovered SCTP I felt so sad for all time I and hundred others had implemented part of its featureset over the last 30 years... I mean, it was packed with great features like separate streams, packet-based, multi-homing and multipath. It felt so right playing with it. Alas, even in my company I failed to convince it was a great replacement for layers upon layers of working udp code. I think it came too late...
> Every app has to implement it itself rather than calling a syscall and letting the OS deal with its complexities
I think for almost all developers, library support for features is much more relevant than OS support anyway. How many of you are directly writing winsock code? Implementing it on UDP just means that you don't need to update a lot of ancient routers and firmware.
I don't see "ossification" being a problem. Things haven't changed much at the transport layer because largely it just works.
> Things haven't changed much at the transport layer because largely it just works.
There is a reason this isn't built on top of TCP, because TCP has so many problems the moment you try to do anything non trivial with it.
UDP on the other hand is kind of redundant since you already have IP packages, so you have a tiny package based protocol on top of a different package based protocol. Also you don't get any ordering information in UDP, which is kind of weird since the IP layer has to handle ordering to deal with package fragmentation, which is a fun feature that some hardware sees as a request to reorder your packages. I may have some PTSD from dealing with "smart" switches and a bit of software that did not expect package reordering issues on a tiny in house network.
i think the intent is that normally you would do a lot of syscalls in order to do networking; with QUICK you would currently be forced to do do zero-copy networking and pass the frames to the kernal via pf-ring; things don't become simpler, as the network layers will have to be handled by a user mode library, however they would potentially be much faster.
Those work and will reduce the system call overhead. But testing showed that it isn't actually the main culprit (e.g. you might gain 5% efficiency by going for it).
A far bigger bottleneck with the kernel stack is that e.g. the route lookup, iptable rules and similar things will be evaluated per packet - which is taking up most of the time. That will happen independent of you deliver one packet per system call or multiple of those.
UDP Generic segmentation offload (GSO - https://lwn.net/Articles/752184/) reduces that overhead by amortizing all in-kernel and driver operations over batches of datagrams. It makes a far bigger difference in efficiency than purely reducing syscalls (e.g. to +100% efficiency - but it will all depend on the other work the application and QUIC stack does and what drivers support).
> Every app has to implement it itself rather than calling a syscall and letting the OS deal with its complexities (same as for TLS, making fewer apps implement it without a lot of extra work)
{kind=link}
But it's still just a layer on top of UDP, and still implemented at the application, like in the past. So how is the ossification broken?
Every app has to implement it itself rather than calling a syscall and letting the OS deal with its complexities (same as for TLS, making fewer apps implement it without a lot of extra work). Which also increases context switching. In the future more protocols will be built on top of QUIC, expanding the user-space stack, increasing fragmentation of application-space IP stacks. And are network cards now going to start implementing it?
It's painful to watch us stride headlong into the future depending on band-aids because surgery is too complicated.